نیاز به ذخیره یک صفحه وب یا وب سایت دارید تا بتوانید آن را به صورت آفلاین مشاهده کنیدآیا برای مدت زمان طولانی به طور آفلاین هستید، اما میخواهید از طریق وبسایت مورد علاقه خود مرور کنید؟ اگر شما از فایرفاکس استفاده می کنید، یک افزونه فایرفاکس وجود دارد که می تواند مشکل شما را حل کند.
ضبط بروشور یک فایرفاکس بسیار جذاب است که کمک می کند شما برای ذخیره صفحات وب و سازماندهی آنها در بسیار آسان برای مدیریت راه. چیز بسیار جالبی در مورد این افزودنی این است که بسیار آسان، سریع و دقیق کپی محلی یک صفحه وب تقریبا کامل و پشتیبانی از چندین زبان را پشتیبانی می کند.
شما می توانید از Scrapbook برای اهداف زیر استفاده کنید:
نصب بخشنامه
اگر شما در حال اجرا آخرین نسخه فایرفاکس، که v33 برای من از این نوشتن است، شما باید تنظیم برخی از تنظیمات به طوری که شما می توانید از ScrapBook به درستی استفاده کنید. به طور پیشفرض، نماد ScrapBook در هر مکان نمایش داده نخواهد شد، بنابراین تنها راه استفاده از آن، اگر شما بر روی یک صفحه وب راست کلیک کنید.

سفارشیرا انتخاب کنید. در صفحه سفارشی، نماد ScrapBook را در سمت چپ ببینید. برو جلو و آن را به هر دو نوار ابزار در بالای صفحه یا منو بکشید.
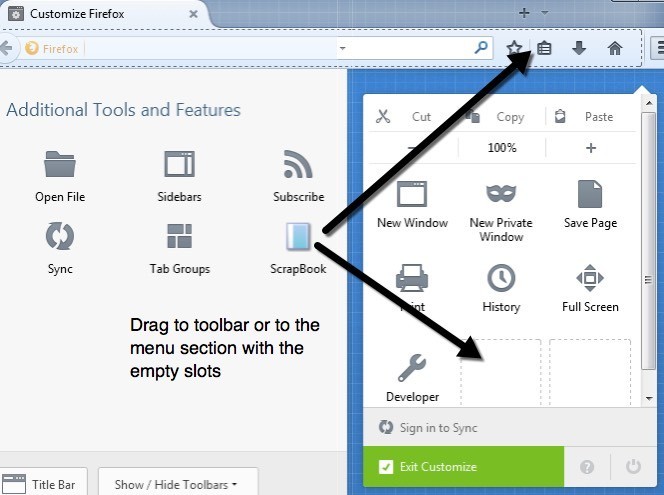
قبل از استفاده از Scrapbook برای صرفه جویی در یک وب سایت، بر روی دکمه Exit Customizeکلیک کنید. ، ممکن است بخواهید تنظیمات افزودنی را تغییر دهید.
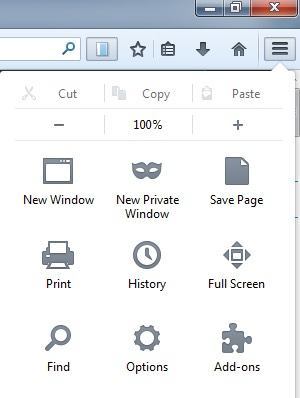 شما می توانید این کار را با کلیک کردن بر روی دکمه منو در سمت راست بالا (سه خط افقی) و سپس کلیک بر روی افزونه هاانجام دهید. / p>
شما می توانید این کار را با کلیک کردن بر روی دکمه منو در سمت راست بالا (سه خط افقی) و سپس کلیک بر روی افزونه هاانجام دهید. / p>
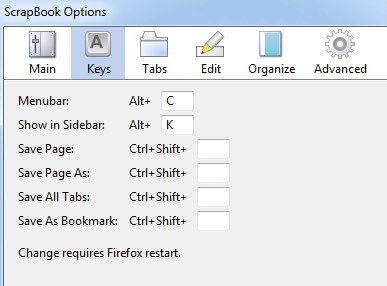
اکنون بر روی برنامه های افزودنیکلیک کنید و سپس بر روی دکمه گزینهدر کنار افزونه ScrapBook کلیک کنید.

در اینجا می توانید میانبرهای صفحه کلید، مکان ذخیره سازی داده ها و دیگر تنظیمات جزئی را تغییر دهید.
استفاده از ScrapBook برای دانلود سایتها
حالا اجازه دهید جزئیات دقیق استفاده از برنامه را بدانیم. اول، وب سایت را که میخواهید صفحات وب را بارگیری کنید، بارگیری کنید. ساده ترین راه برای شروع دانلود، کلیک راست روی هر صفحه در صفحه است و یا ذخیره صفحهیا ذخیره صفحه به عنوانرا به سمت پایین منو انتخاب کنید.

صفحه ذخیره به شما اجازه می دهد تا یک پوشه را انتخاب کرده و سپس فقط صفحه کنونی را ذخیره کنید. اگر می خواهید گزینه های بیشتر، که من معمولا انجام می دهند، روی گزینه Save Page As کلیک کنید. شما یک گفتگوی دیگر دریافت خواهید کرد که در آن می توانید از گزینه های زیادی انتخاب کنید.

بخش های مهم گزینه، دانلود فایل های مرتبط شده، و سپس در -depth ذخیرهگزینه ها.
بخش دانلود فایل های پیوند شده فقط تصاویر مرتبط را دانلود می کند، اما شما همچنین می توانید برای تلفن های موبایل، فیلم ها فایل ها، فایل های بایگانی یا مشخص کردن نوع دقیق فایل ها برای دانلود. این گزینه واقعا مفید است اگر شما در وب سایت هستید که دارای تعداد زیادی لینک به یک نوع خاص از فایل (ورد docs، PDFs، و غیره) است و شما می خواهید تمام فایل های مرتبط را به سرعت دانلود کنید.
در نهایت، گزینه عمیق ذخیرهاین است که چگونه از قسمتهای بزرگتر وب سایت دانلود کنید. به طور پیش فرض، آن را به 0 تنظیم شده است، به این معنی که هیچ پیوند به سایر صفحات سایت و یا هر لینک دیگر مربوط به آن را دنبال نخواهد کرد. اگر یکی را انتخاب کنید، صفحه فعلی و همه چیز را که از آن صفحه مرتبط است، دانلود کنید.

با کلیک بر روی دکمه Save کلیک کنید. عمق 2 از صفحه فعلی، صفحه 1 لینک شده و هر پیوند از صفحه 1 لینک می شود. و پنجره جدید ظاهر خواهد شد و صفحات شروع به دانلود می شوند. شما می خواهید فورا دکمه مکثرا فشار دهید و اجازه دهید به شما بگویم چرا. اگر شما فقط اجازه دهید ScrapBook اجرا شود، شروع به دانلود همه چیز از صفحه، از جمله تمام موارد موجود در کد منبع است که ممکن است به یک دسته از سایت های دیگر یا شبکه های تبلیغاتی پیوند دهد. همانطور که در تصویر بالا دیده می شود، خارج از سایت اصلی (labnol.org)، آن را از تبلیغات googleadservices.com و چیزی از ctrlq.org دانلود می کند.
آیا واقعا می خواهید تبلیغات نمایش داده شود در حالی که شما در حال دیدن آن آنلاین نیستید؟ این نیز مقدار زیادی از زمان و پهنای باند را هدر خواهد داد، بنابراین بهترین کار این است که دکمه Pause را فشار داده و سپس بر روی دکمه فیلترکلیک کنید.

بهترین دو گزینه محدود به دامنهو محدود به فهرستاست. به طور معمول این ها یکسان هستند، اما در سایت های خاص آنها متفاوت خواهند بود. اگر دقیقا چه صفحاتی را می خواهید بدانید، می توانید حتی با رشته فیلتر کنید و URL خود را تایپ کنید. این گزینه شگفت انگیز است زیرا از همه ی آشغال های دیگر خلاص می شود و فقط محتوای وب سایت واقعی شما را به جای سایت های اجتماعی، شبکه های تبلیغاتی و غیره دانلود می کند.
برو جلو و روی شروعو صفحات شروع به دانلود می کنند. زمان بارگیری بسته به سرعت اتصال اینترنت شما و دقیقا چقدر در وب سایت شما بارگیری می شود. افزودنی برای بسیاری از سایت ها بسیار عالی عمل می کند و تنها موضوعی که من به آن دست زدم این است که در برخی از سایت ها URL هایی که برای ارتباط با محتوای خود استفاده می کنند URL های مطلق هستند.
مشکل با URL های مطلق این است که هنگام باز کردن صفحه فهرست در فایرفاکس در حالت آفلاین و تلاش برای کلیک روی هر یک از پیوندها، سعی خواهد کرد از وبسایت واقعی، نه از حافظه داخلی بارگیری کند. در این موارد، باید پوشه دانلود را به صورت دستی باز کنید و صفحات را باز کنید. این درد است و من فقط آن را در تعداد انگشت شماری از سایت ها اتفاق می افتد، اما این اتفاق می افتد. شما می توانید پوشه دانلود را با کلیک کردن بر روی دکمه اسکناس بر روی نوار ابزار خود و سپس کلیک راست بر روی سایت و انتخاب ابزار- نمایش فایل هامشاهده کنید.
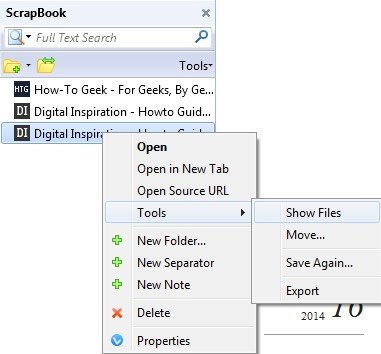
در اکسپلورر، مرتب سازی بر اساس نوعو سپس به فایل های به نام HTML Document بروید.صفحات محتوا به طور معمول فایل های default_00x هستند نه فایل index_00x.
اگر شما از فایرفاکس استفاده نمی کنید و هنوز هم می خواهید برای دانلود صفحات وب به رایانه شما، همچنین می توانید از نرم افزار WinHTTrack که به صورت خودکار تمام وب سایت را برای مرور در اینترنت آفلاین دانلود کنید، را بررسی کنید. با این حال، WinHTTrack مقدار زیادی از فضای مورد استفاده را می گیرد، بنابراین مطمئن شوید فضای آزاد کافی در هارد دیسک خود دارید.
هر دو برنامه به خوبی برای دانلود وب سایت های کل یا برای دانلود صفحات وب به خوبی کار می کنند. در عمل، دانلود یک کل وب سایت تقریبا غیرممکن است زیرا شمار زیادی از پیوندهایی که توسط نرم افزار CMS مانند وردپرس و غیره ایجاد شده است. اگر شما هر گونه سوال دارید، نظر خود را ارسال کنید. لذت ببرید!